
Japanese Text Translation on Heroku.
This is a single-page web application which takes Japanese text input in the left panel, separates that text into sections, looks up dictionary definitions for the words within, and presents them to you for easy scanning. For example, you can try it out with:
...and get an output like:Sample text wrote: ばか!バカ! 馬鹿ー月!
十年目の記念日、おめでとうございます!
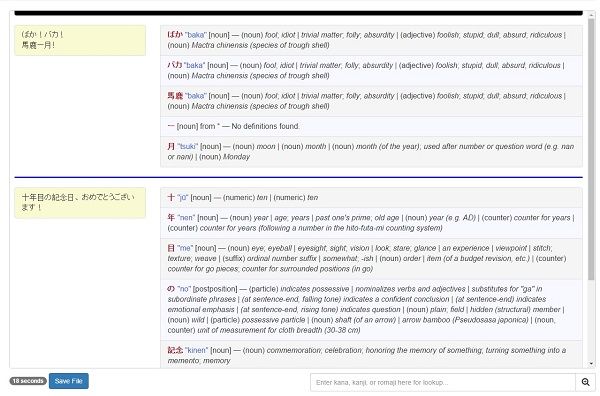
You can also perform quick dictionary lookups on specific terms using the input on the bottom-right of the page. For example, try 記念日, and see how it's different from the text translation. A more in-depth tutorial on of how to use the tool is available from the information button on the top-right corner of the page.
This tool was based on the WWWJDIC text glossing tool and takes its dictionary, but adds a substantially different user interface. I decided to make the tool after contemplating my experience of using WWWJDIC to translate volume four of Rakudai Kishi no Eiyuutan over the course of one and a half months with daily updates, an experience that was predominantly about balancing the effort of reading gigantic blocks of JDIC output from submitting large passages (try using the sample text above in WWWJDIC, and imagine that going on for pages) against the effort of manually splitting passage into more manageable pieces and then submitting them individually (a workflow which involves four active windows: the text to be copied from, the translation to be written into, WWWJDIC itself, and the original source for error checking). After a period of philosophical meditation, I concluded that this experience was total flaming garbage (although the readers seemed happy about the daily updates), so I examined my workflow and tried to identify where it could be facilitated. This tool is a result of that exercise, and I'd like to spread the benefits to the rest of the community. Please try out the version above and see if it does benefit you.
Technical matters: Heroku, the cloud platform on which the application is deployed, imposes rather severe limitations in exchange for being free, making the application's performance considerably worse. For example:
- It may take you a long time to even go to the link I provided. This is because Heroku sleeps the application when it is idle for a while, and now it must spin up again, and until that happens the page is blank. Please wait.
- It may happen that a translation completely fails. The cause is probably either your text is so long that an atomic part of the query timed out on Heroku's enforced thirty-second limit, or Heroku just randomly dropped your query. This behavior is unfortunately not predictable, especially under the load of multiple users, so all I can say is try it again, keeping your text to around sub-chapter length. Lookups are usually not penalized by this, because they are much simpler.
- It generally takes a long time to translate a text, much longer than the equivalent text in WWWJDIC. Heroku is slower than the application is on localhost; it takes about two minutes to translate a test case of about ten pages on Heroku, while I've successfully translated an entire 300+ page light novel in under a minute using localhost (though that suffers other technical issues which make it currently unfeasible for general deployment). In particular, starting a translation tends to have the progress spinner begin, but the progress bar does not move for a long time. This is because Heroku is taking a long time to perform the text pre-processing before the actual translation measured by the progress bar, but yes the app is actually working (unless Heroku fails the pre-processing step, see above).
But that would depend on people actually using and liking it (or at least the idea of it, if not the performance of the Heroku deployment). And on the administration not hammering it as quasi-machine translation. I've used this program's prototypes for translating a number of manga chapters, and it makes my work more pleasant. I hope it helps others as well.
